A
Bonjour à tous,
Je suis en train de programmer un petit parseur de fichier SWF pour mon bot.
Pour celà, j'ai récupéré la doc de spécification des fichiers SWF d'Adobe.
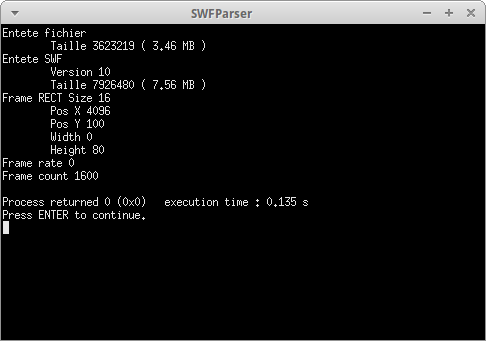
J'ai codé la partie lecture de l'entête du fichier (8 premiers octets) et je dois donc ensuite décompresser le reste du fichier à l'aide de la bibliothèque zlib sous Linux. Mais j'arrive à un petit problème, l'initialisation de la zlib donne un "segmentation fault" et comme je pense que je suis un gros boulet, je n'arrive pas à comprendre d'où vient l'erreur.
Voici le code de ma classe SwfFile : https://github.com/wamilou/SwfParser/bl ... wfFile.cpp
Quand je debug mon programme, le segfault apparait à la ligne 76, la plupart du code utilisé vient du site officiel de zlib et aussi les 2 tableaux in et out font la taille du fichier et la taille du swf final respectivement ( ce qui n'est pas très bon je l'avoue si le fichier est très gros x) )
Donc je me demandais, s'il y avait des gens ici qui ont utilisé zlib et s'ils ont eu ce problème comme moi, car là, je suis repassé plusieurs fois sur mon code pour voir si j'avais pas fait d'erreur monstrueuse mais j'ai toujours ce problème de segmentation fault (surement j'ai mal initialisé la structure ?)
Merci d'avance pour votre aide !
PS : Mon code est dégueulasse, mais j'aimerai fixer ce problème avant d'optimiser x)
Je suis en train de programmer un petit parseur de fichier SWF pour mon bot.
Pour celà, j'ai récupéré la doc de spécification des fichiers SWF d'Adobe.
J'ai codé la partie lecture de l'entête du fichier (8 premiers octets) et je dois donc ensuite décompresser le reste du fichier à l'aide de la bibliothèque zlib sous Linux. Mais j'arrive à un petit problème, l'initialisation de la zlib donne un "segmentation fault" et comme je pense que je suis un gros boulet, je n'arrive pas à comprendre d'où vient l'erreur.
Voici le code de ma classe SwfFile : https://github.com/wamilou/SwfParser/bl ... wfFile.cpp
Quand je debug mon programme, le segfault apparait à la ligne 76, la plupart du code utilisé vient du site officiel de zlib et aussi les 2 tableaux in et out font la taille du fichier et la taille du swf final respectivement ( ce qui n'est pas très bon je l'avoue si le fichier est très gros x) )
Donc je me demandais, s'il y avait des gens ici qui ont utilisé zlib et s'ils ont eu ce problème comme moi, car là, je suis repassé plusieurs fois sur mon code pour voir si j'avais pas fait d'erreur monstrueuse mais j'ai toujours ce problème de segmentation fault (surement j'ai mal initialisé la structure ?)
Merci d'avance pour votre aide !
PS : Mon code est dégueulasse, mais j'aimerai fixer ce problème avant d'optimiser x)
")